Model-Driven Approach of Virtual Interactive Environments for Enhanced User Experience (source)
Keywords: User Experience, Virtual Environment, Model-Driven Architecutre (MDA)
The video game and entertainment industry has been growing in recent years, particularly those related to Virtual Reality (VR). Therefore, video game creators are looking for ways to offer and improve realism in their applications in order to improve user satisfaction. In this sense, it is of great importance to have strategies to evaluate and improve the gaming experience in a group of people, without considering the fact that users have different preferences and, coupled with this, also seeks to achieve satisfaction in each user. In this work, we present a model to improve the user experience in a personal way through reinforcement learning (RL). Unlike other approaches, the proposed model adjusts parameters of the virtual environment in real-time based on user preferences, rather than physiological data or performance. The model design is based on the Model-Driven Architecture (MDA) approach and consists of three main phases: analysis phase, design phase, and implementation phase. As results, a simulation experiment is presented that shows the transitions between undesired satisfaction states to desired satisfaction states, considering an approach in a personal way.
Model to Evaluate and Improve User Experience
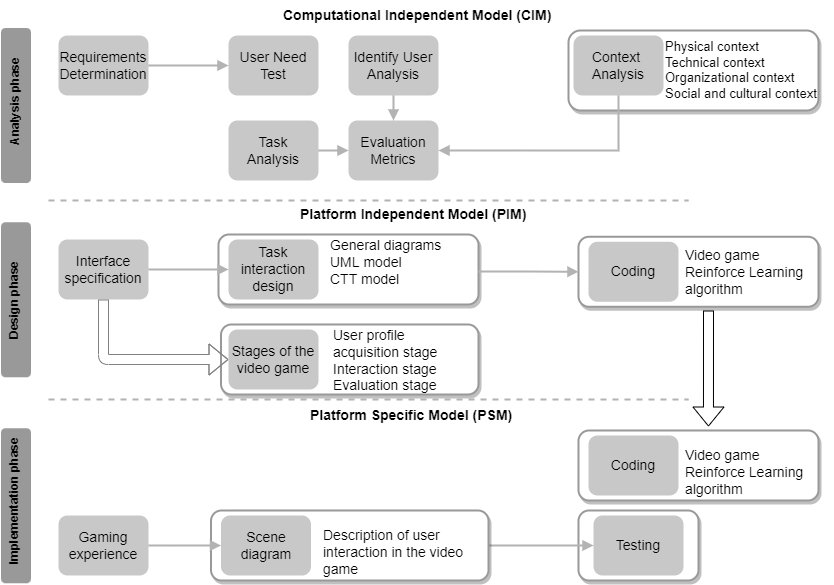
This section presents a model that allows virtual environments to be adapted to the user’s preferences in a personal way. This is intended to improve satisfaction and avoid negative outcomes while interacting with the virtual environment. The model considers RL and MDA strategies in its design. For the design of the proposed model in the figure below, it takes as a basis the fundamentals of the MDA approach for the design of virtual environments that can be adapted to the user’s needs. The proposed model is composed of the following phases:
- 1. Computation-Independent Model (CIM), established as an analysis phase, in this phase the system and user tasks are defined, as well as the context tools..
- 2. The Platform-Independent Model (PIM), is described as a design phase, in this phase the virtual environment interface and design diagrams—general system diagrams, UML model, and CTT notation—are required to define the interaction between elements and the process..
- 3. The Platform-Specific Model (PSM), as the implementation phase, which consists of the virtual environment experience, the description of the user interaction, and a testing stage from a Software Engineering (SWE) and Human–Computer Interaction (HCI) perspective.
Analysis phase
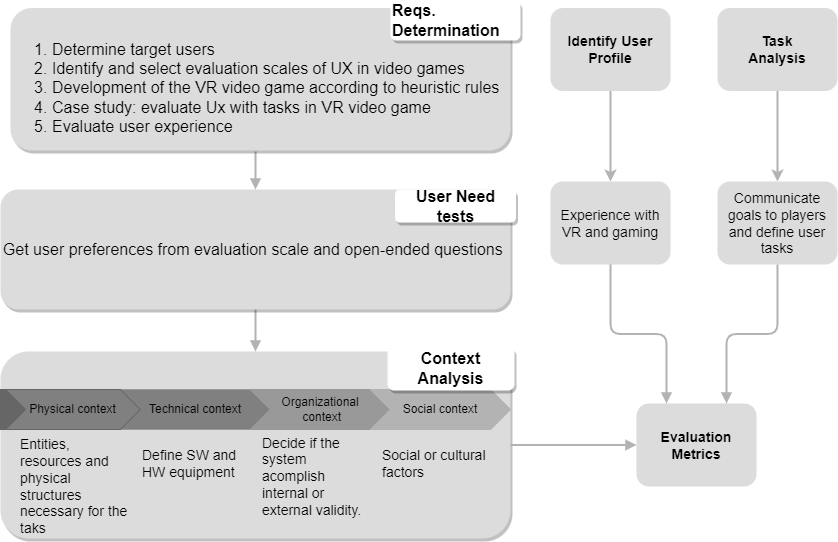
As illustrated in Figure below. This phase starts with the development process to establish the modeling in the context of the virtual environment requirements. It is mainly composed of the determination of the requirements of the virtual environment, the determination of the user’s needs, and the context on which the virtual environment will be executed. The parts that make up the analysis stage are described below.
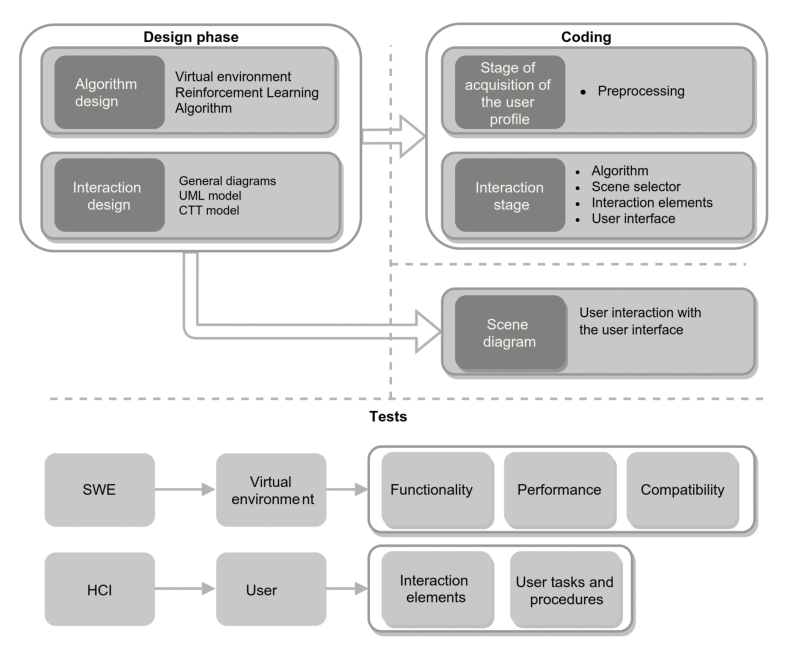
Design phase
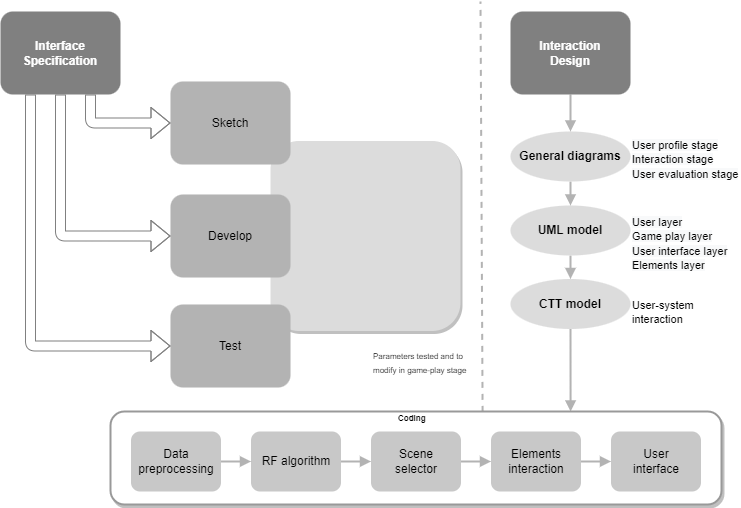
According to the figure below, the interface is specified and then an interaction design of the virtual environment is presented. The interface specification and interaction design are based on the user acquisition stage of the user profile, user interaction, and user evaluation.
Interface specification
The interface specification concentrates on a representation of the environment. It consists of making a sketch of the user interface.
User Interaction Design
In user interaction (formal representation of the environment), general diagrams of the environment are made as part of the system design (UML models) to represent the structure and interaction between system elements, and a Concur Task Tree (CTT) notation that shows the process for representing and completing a task (e.g., the steps a user has to follow to make a record or steps a player has to follow to finish a mission).
Algorithm Design
The core elements of the design phase are based on two stages: user profile acquisition stage, interaction stage. The user profile acquisition stage: To obtain user preferences, a user profile acquisition stage is required, which consists of generating different states of satisfaction (data preprocessing) from a set of environment customization parameters (e.g., changes in environment elements, difficulty in the environment and time to complete the objectives). To define these states, a testing stage should be considered for a period of time, either in a dynamic demonstration or questions in the user interface. The user interaction stage: it consists of the interaction between the user and the environment, where the reinforcement learning algorithm adjusts the virtual environment in a personal way for each user by switching between states (e.g., missions, levels, or a set of parameters that redefine the difficulty) that are translated into states of user satisfaction.
Implementation phase
As illustrated in Figure below. This phase starts with the development process to establish the modeling in the context of the virtual environment requirements. It is mainly composed of the determination of the requirements of the virtual environment, the determination of the user’s needs, and the context on which the virtual environment will be executed. The parts that make up the analysis stage are described below.
Implementation of Proposed Model
This section presents the implementation of the proposed model through the development of a virtual environment in which a reinforcement learning algorithm that takes into account the user’s preferences is implemented. Next, the stages proposed for the implementation under the proposed model are described.
Analysis phase
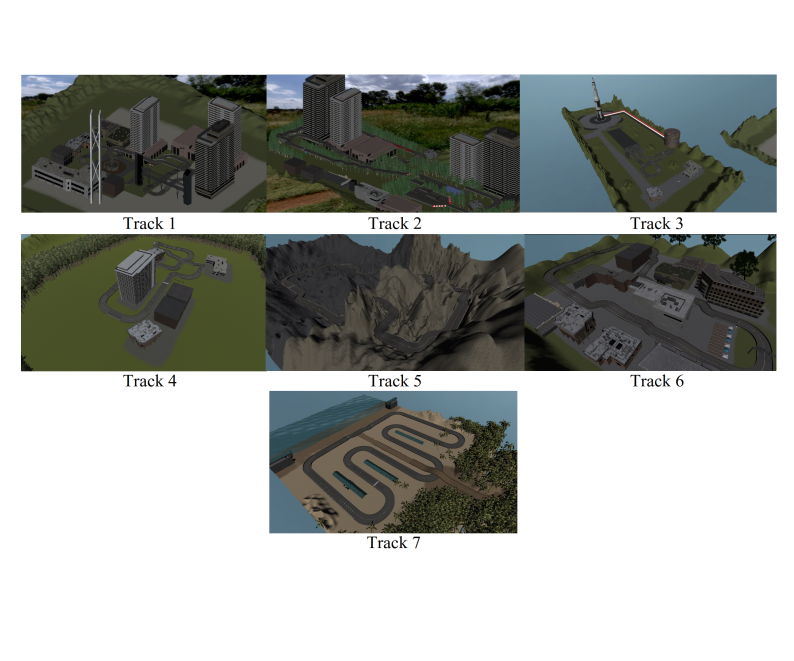
he virtual environment consists of a single-player racing video game. The video game is an adaptation of a template named: Karting Microgame, this template is an open project racing game available on the Unity3D platform. This template initially consists of a track and 3 laps. Subsequently, the implementations were made to the virtual environment according to the proposed template. The virtual environment is composed of the design of seven different tracks, as shown in Figure below. Each track presents a particular design in which the same style of its visual elements is preserved.
The player could control a cart, collect coins, and avoid obstacles. The cart can move in all directions, jump, crash, and skid. In addition, the player has to navigate the whole track to finish the lap. The player starts at the lap control point and has to perform 3 laps to finish a track. During the game, the player interacts with static and dynamic elements. In addition, the player must avoid obstacles and collect coins that appear along the way. The player collects a coin, a coin counter that appears on the user interface changes, and the player gets a point. The game ends when the user reaches the maximum state of satisfaction.
Design phase
Environment and Algorithm Design
In this stage, the user uses the virtual environment with the goal of the RL algorithm to help improve the UX. First, the user enters the system, and an unpleasant state/track (s0,s1,s2) is randomly assigned to start the interaction. During the track, the user can perform the following interactions: collect coins along the way to obtain scores, avoid obstacles along the way, and complete 3 laps to finish a track. Upon completion of each track, the algorithm transitions to another state/track, from st to st+1 and collects the data of time per lap, total time duration per track, coins collected, and obstacles hit for further analysis. Once users reach the desired state, interaction with the game concludes.
User Profile Acquisition Stage
At this stage, a set of states were defined based on configurable parameters, such as speed, music, and the number of obstacles (Table below). To define the states, test sessions were conducted with a duration of 5 min, where the player used the virtual environment, then proceeded to generate the states of satisfaction.
| Parameter | Mode | Description |
|---|---|---|
| Speed | S1 | Speed is set at 10 km/h. |
| S2 | The speed is set at 15 km/h. | |
| S3 | The speed is set at 20 km/h. | |
| Music | M1 | Song: Tusa by Karol G and Nicki Minaj |
| M2 | Canción: Sex on Fire de Kings of Leon | |
| M3 | Song: You’ll Be Under My Wheels by The Prodigy | |
| Obstacles | O1 | Less than 10 obstacles on the track |
| O2 | Between 10 and 20 obstacles on the track | |
| O3 | Between 20 and 30 obstacles on the track |
Design phase
Next figure represents the user preferences process. First, the user enters a testing stage and chooses an option to acquire his preferences, said preferences can be obtained from the following options, Option 1: the user enters the test and, once in the test, selects the parameters he/she finds satisfactory. Option 2: the user enters the test and once it is completed, the user selects the preferred parameters.
Then the user’s preferences are obtained, the data is preprocessed. Here, a combination of the parameters is assigned to a set of satisfaction states St={s0,s1,s2,…,s6}—states corresponding to the Q-learning algorithm. Subsequently, a reward matrix is generated from the defined states. The mapping of the states with the combination of the parameters is presented in the Table below.
| State | Track | Parameters | ||
|---|---|---|---|---|
| Speed | Music | Number of Obstacles | ||
| S0 | 0 | least preferred | least preferred | least preferred |
| S1 | 1 | least preferred | neutral preferred | least preferred |
| S2 | 2 | least preferred | neutral preferred | neutral preferred |
| S3 | 3 | neutral preferred | neutral preferred | neutral preferred |
| S4 | 4 | most preferred | neutral preferred | neutral preferred |
| S5 | 5 | most preferred | most preferred | neutral preferred |
| S6 | 6 | most preferred | most preferred | most preferred |
Implementation phase
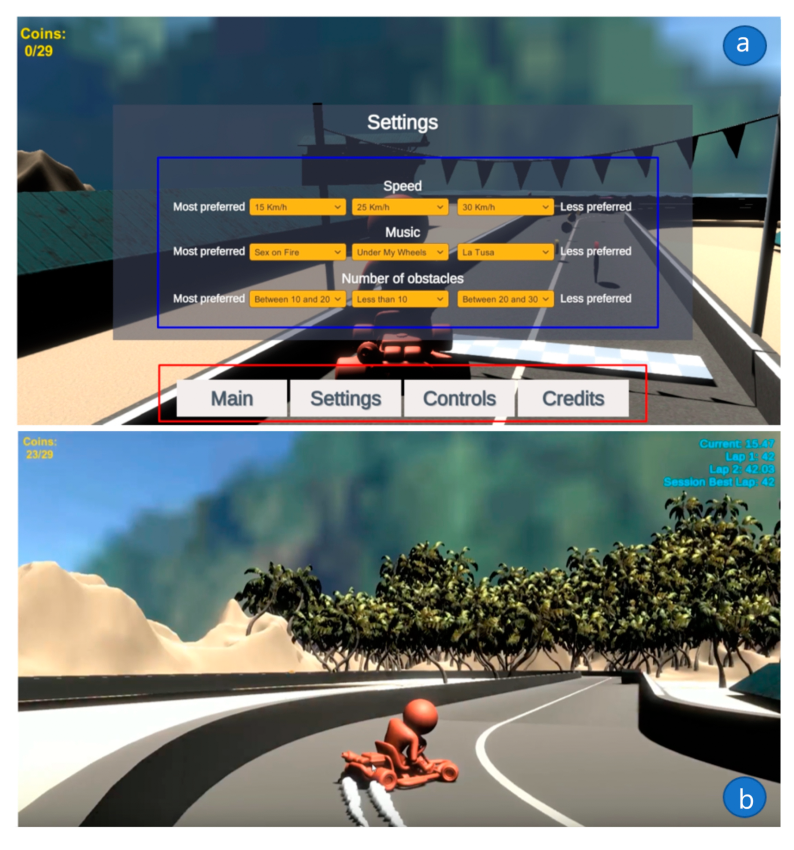
Figure bellow illustrates the user’s profile acquisition interface, and also shows a main rectangle (enclosed in blue) where the player chooses the speed, music, and the number of obstacles. At the bottom of the same image, some buttons are observed wherein “Main”, the instructions of the virtual environment are indicated; “Settings”, user preferences configuration; “Controls”, the controls to move the cart; and “Credits”, developer credits. The track interface Figure 15b presents in the upper right corner feedback information to the user, such as time per lap, current time, and current lap number, in the upper left corner we can find the collected coins and totals in the track.
Results
The results obtained from the implementation of the model were the product of three different simulations. These simulations correspond to the user profile acquisition stage, simulating that three users played during 5 min trials and defined the parameters of speed, music, and the number of obstacles. These tests allowed validating the implementation within the virtual environment of the RL algorithm.
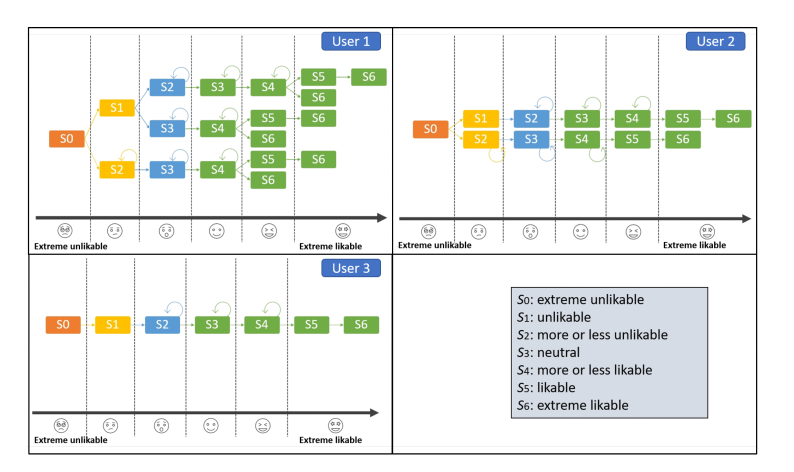
The following figure shows the transitions in each state, this depends on the Q-table which is a function of the reward matrix. According to Figure, the user starts in state extremely unlikable (S0) and has the possibility to go to state unlikable (S1) or to state more or less unlikable (S2) because they have the minimum reward, in S2 the algorithm has the option to stay in the same state or transition to the state neutral (S3), and so on until it reaches the state extremely likable (S6).
This work presents a model to adapt virtual environments to users in order to get good experience with the technology. The model allows us to adjust a series of parameters of a virtual environment using a reinforcement learning technique, which adapts to the user’s preferences. The design of the phases of the model based on an MDA architecture is presented, then in the implementation of the model a video game is developed, and the proposed model is applied to a case study with simulations. Here, some advantages related to current proposal.
Conclusions
This work proposes a model under the MDA approach that offers developers and researchers a means to establish the various levels of abstraction for adequate identification of the profiles involved and thus define the development phases of the virtual environment and the objectives. At the same time, this model proposes Reinforcement Learning as a technique to offer a good user experience in virtual environments according to the player’s preferences and the setting of parameters of the environment in a personal way. However, future work is vast, and it is necessary to further emphasize the user-centered approach to the design of the virtual environment, leading to its evaluation and feedback from users.